
areal
from shapely.geometry import Polygon
import numpy as np
%matplotlib inline
import geopandas as gpd
from tobler import area_weighted
from tobler.area_weighted import area_tables, area_interpolate
polys1 = gpd.GeoSeries([Polygon([(0,0), (10,0), (10,5), (0,5)]),
Polygon([(0,5), (0,10), (10,10), (10,5)])])
polys2 = gpd.GeoSeries([Polygon([(0,0), (5,0), (5,7), (0,7)]),
Polygon([(5,0), (5,10), (10,10), (10,0)]),
Polygon([(0,7), (0,10), (5,10), (5,7) ])
])
df1 = gpd.GeoDataFrame({'geometry': polys1})
df2 = gpd.GeoDataFrame({'geometry': polys2})
df1['population'] = [ 500, 200]
df1['pci'] = [75, 100]
df1['income'] = df1['population'] * df1['pci']
df2['population'] = [ 500, 100, 200]
df2['pci'] = [75, 80, 100]
df2['income'] = df2['population'] * df2['pci']
ax = df1.plot(color='red', edgecolor='k')

ax = df2.plot(color='green', alpha=0.5, edgecolor='k')
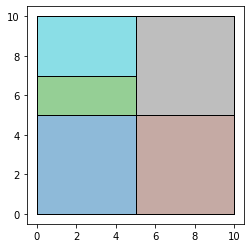
res_union = gpd.overlay(df1, df2, how='union')
ax = res_union.plot(alpha=0.5, cmap='tab10')
df1.plot(ax=ax, facecolor='none', edgecolor='k');
df2.plot(ax=ax, facecolor='none', edgecolor='k');
area_tables(df1, df2)
area_tables(df2, df1)
extensive_vars = ['population', 'income']
intensive_vars = ['pci']
estimates = area_interpolate(df1, df2, extensive_variables = extensive_vars,
intensive_variables = intensive_vars)
estimates
extensive_vars = ['population', 'income']
intensive_vars = ['pci']
estimates = area_interpolate(df2, df1, extensive_variables = extensive_vars,
intensive_variables = intensive_vars)
estimates
polys1 = gpd.GeoSeries([Polygon([(0,0), (12,0), (12,5), (0,5)]),
Polygon([(0,5), (0,10), (10,10), (10,5)])])
polys2 = gpd.GeoSeries([Polygon([(0,0), (5,0), (5,7), (0,7)]),
Polygon([(5,0), (5,10), (10,10), (10,0)]),
Polygon([(0,7), (0,10), (5,10), (5,7) ])
])
df1 = gpd.GeoDataFrame({'geometry': polys1})
df2 = gpd.GeoDataFrame({'geometry': polys2})
df1['population'] = [ 500, 200]
df1['pci'] = [75, 100]
df1['income'] = df1['population'] * df1['pci']
df2['population'] = [ 500, 100, 200]
df2['pci'] = [75, 80, 100]
df2['income'] = df2['population'] * df2['pci']
ax = df1.plot(color='red', edgecolor='k')
df2.plot(ax=ax, color='green',edgecolor='k')
extensive_vars = ['population']
intensive_vars = ['pci']
estimates = area_interpolate(df1, df2, extensive_variables = extensive_vars,
intensive_variables = intensive_vars)
estimates
estimates[0].sum()
extensive_vars = ['population']
intensive_vars = ['pci']
estimates = area_interpolate(df1, df2, extensive_variables = extensive_vars,
intensive_variables = intensive_vars,
allocate_total=False)
estimates
estimates[0].sum()
When setting allocate_total=False the total population of a source zone is not completely allocated, but rather the proportion of total population is set to the area of intersection over the area of the source zone.
This will have no effect when the source df is df2 and the target df is df 1:
extensive_vars = ['population']
estimates = area_interpolate(df2, df1, extensive_variables = extensive_vars)
estimates
extensive_vars = ['population']
estimates = area_interpolate(df2, df1, extensive_variables = extensive_vars, allocate_total=False)
estimates