
Example_NYCBikes_AllFeatures
from pysal.contrib.spint.gravity import BaseGravity, Gravity, Production, Attraction, Doubly
from pysal.contrib.spint.dispersion import phi_disp
from pysal.contrib.spint.vec_SA import VecMoran
import pysal as ps
import pandas as pd
import geopandas as gp
import numpy as np
import seaborn as sb
import matplotlib.pylab as plt
%pylab inline
from descartes import PolygonPatch
import matplotlib as mpl
from mpl_toolkits.basemap import Basemap
import pyproj as pj
from shapely.geometry import Polygon, Point
#Load NYC bike data - trips between census tract centroids
bikes = pd.read_csv(ps.examples.get_path('nyc_bikes_ct.csv'))
bikes.head()
#Process data
#Remove intrazonal flows
bikes = bikes[bikes['o_tract'] != bikes['d_tract']]
#Set zero attirbute values to a small constant
bikes.ix[bikes.o_sq_foot == 0, 'o_sq_foot'] = 1
bikes.ix[bikes.d_sq_foot == 0, 'd_sq_foot'] = 1
bikes.ix[bikes.o_cap == 0, 'o_cap'] = 1
bikes.ix[bikes.d_cap == 0, 'd_cap'] = 1
bikes.ix[bikes.o_housing == 0, 'o_housing'] = 1
bikes.ix[bikes.d_housing == 0, 'd_housing'] = 1
#Flows between tracts
flows = bikes['count'].values.reshape((-1,1))
#Origin variables: square footage of buildings, housing units, total station capacity
o_vars = np.hstack([bikes['o_sq_foot'].values.reshape((-1,1)),
bikes['o_housing'].values.reshape((-1,1)),
bikes['o_cap'].values.reshape((-1,1))])
#Destination variables: square footage of buildings, housing units, total station capacity
d_vars = np.hstack([bikes['d_sq_foot'].values.reshape((-1,1)),
bikes['d_housing'].values.reshape((-1,1)),
bikes['d_cap'].values.reshape((-1,1))])
#Trip "cost" in time (seconds)
cost = bikes['tripduration'].values.reshape((-1,1))
#Origin ids
o = bikes['o_tract'].astype(str).values.reshape((-1,1))
#destination ids
d = bikes['d_tract'].astype(str).values.reshape((-1,1))
print len(bikes), ' OD pairs between census tracts after filtering out intrazonal flows'
#First we fit a basic gravity model and examine the parameters and model fit
grav= Gravity(flows, o_vars, d_vars, cost, 'exp')
print grav.params
print 'Adjusted psuedo R2: ', grav.adj_pseudoR2
print 'Adjusted D2: ', grav.adj_D2
print 'SRMSE: ', grav.SRMSE
print 'Sorensen similarity index: ', grav.SSI
#Next we fit a production-constrained model
prod = Production(flows, o, d_vars, cost, 'exp')
print prod.params[-4:] #truncate to exclude balancing factors/fixed effects
print 'Adjusted psuedo R2: ', prod.adj_pseudoR2
print 'Adjusted D2: ', prod.adj_D2
print 'SRMSE: ', prod.SRMSE
print 'Sorensen similarity index: ', prod.SSI
#Next we fit an attraction-constrained model
att = Attraction(flows, d, o_vars, cost, 'exp')
print att.params[-4:] #truncate to exclude balancing factors/fixed effects
print 'Adjusted psuedo R2: ', att.adj_pseudoR2
print 'Adjusted D2: ', att.adj_D2
print 'SRMSE: ', att.SRMSE
print 'Sorensen similarity index: ', att.SSI
#Finally, we fit the doubly constrained model
doub = Doubly(flows, o, d, cost, 'exp')
print doub.params[-1:] #truncate to exclude balancing factors/fixed effects
print 'Adjusted psuedo R2: ', doub.adj_pseudoR2
print 'Adjusted D2: ', doub.adj_D2
print 'SRMSE: ', doub.SRMSE
print 'Sorensen similarity index: ', doub.SSI
#Next, we can test the models for violations of the equidispersion assumption of Poisson models
#test the hypotehsis of equidispersion (var[mu] = mu) against that of QuasiPoisson (var[mu] = phi * mu)
#Results = [phi, tvalue, pvalue]
print phi_disp(grav)
print phi_disp(prod)
print phi_disp(att)
print phi_disp(doub)
#We can see for all four models there is overdispersion (phi >> 0),
#which are statistically significant according the tvalues (large)
#and pvalues (essentially zero). It does however decrease as more
#constraints are introduced and model fit increases
#As a result we can compare our standard errors and tvalues for a Poisson model to a QuasiPoisson
print 'Production-constrained Poisson model standard errors and tvalues'
print prod.params[-4:]
print prod.std_err[-4:]
print prod.tvalues[-4:]
#Fit the same model using QuasiPoisson framework
Quasi = Production(flows, o, d_vars, cost, 'exp', Quasi=True)
print 'Production-constrained QuasiPoisson model standard errors and tvalues'
print Quasi.params[-4:]
print Quasi.std_err[-4:]
print Quasi.tvalues[-4:]
#As we can see both models result in the same parameters (first line)
#We also see the QuasiPoisson results in larger standard errors (middle line)
#Which then results in smaller t-values (bottom line)
#We would even consdier rejecting the statistical significant of of the
#parameter estimate on destination building square footage because its abolsute
# value is less than 1.96 (96% confidence level)
#We can also estimate a local model which subsets the data
#For a production constrained model this means each local model
#is from one origin to all destinations. Since we get a set of
#parameter estimates for each origin, we can then map them.
local_prod = prod.local()
#There is a set of local parameter estimates, tvalues, and pvalues for each covariate
#And there is a set of local values for each diagnostic
local_prod.keys()
#Prep geometry for plotting
#Read in census tracts for NYC
crs = {'datum':'WGS84', 'proj':'longlat'}
tracts = ps.examples.get_path('nyct2010.shp')
tracts = gp.read_file(tracts)
tracts = tracts.to_crs(crs=crs)
#subset manhattan tracts
man_tracts = tracts[tracts['BoroCode'] == '1'].copy()
man_tracts['CT2010S'] = man_tracts['CT2010'].astype(int).astype(str)
#Get tracts for which there are no onbservations
mt = set(man_tracts.CT2010S.unique())
lt = set(np.unique(o))
nt = list(mt.difference(lt))
no_tracts = pd.DataFrame({'no_tract':nt})
no_tracts = man_tracts[man_tracts.CT2010S.isin(nt)].copy()
#Join local values to census tracts
local_vals = pd.DataFrame({'betas': local_prod['param3'], 'tract':np.unique(o)})
local_vals = pd.merge(local_vals, man_tracts[['CT2010S', 'geometry']], left_on='tract', right_on='CT2010S')
local_vals = gp.GeoDataFrame(local_vals)
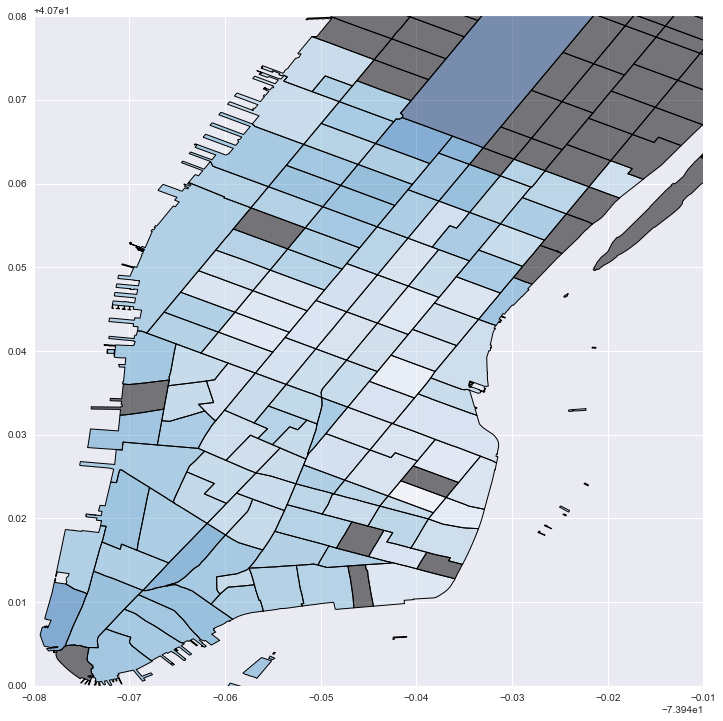
#Plot local "cost" values: darker blue is stronger distance decay; grey is no data
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(111)
local_vals['inv_betas'] = (local_vals['betas']*-1)
no_tracts['test'] = 0
no_tracts.plot('test', cmap='copper', ax=ax)
local_vals.plot('inv_betas', cmap='Blues', ax=ax)
plt.xlim(-74.02, -73.95)
plt.ylim(40.7, 40.78)
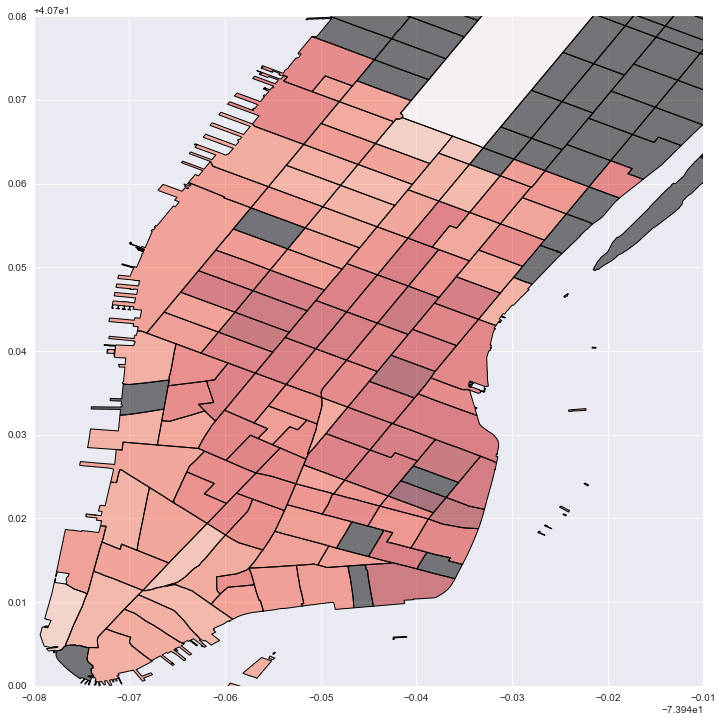
#Plot local estimates for destination capacity: darker red is larger effect; grey is no data
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(111)
local_vals['cap'] = local_prod['param3']
no_tracts['test'] = 0
no_tracts.plot('test', cmap='copper', ax=ax)
local_vals.plot('cap', cmap='Reds', ax=ax)
plt.legend()
plt.xlim(-74.02, -73.95)
plt.ylim(40.7, 40.78)
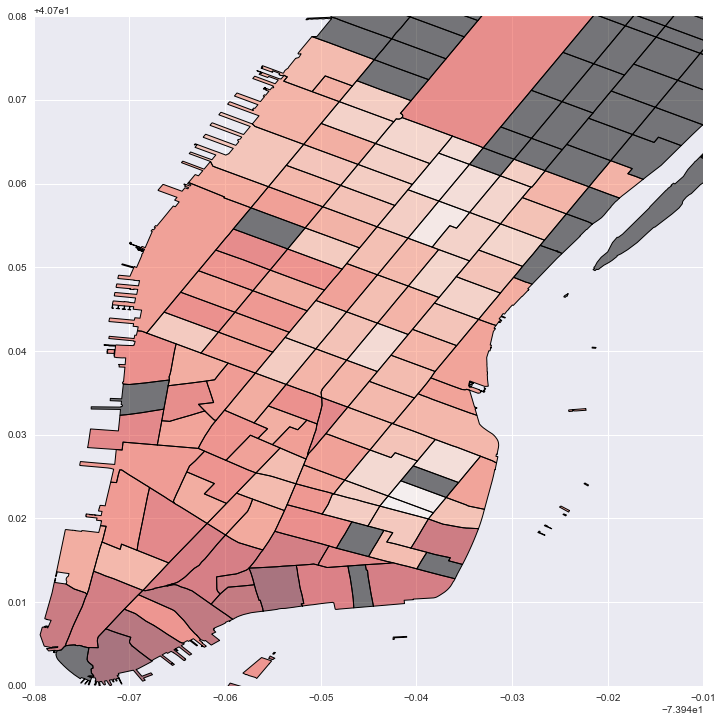
#Plot local estimates for # of housing units: darker red is larger effect; grey is no data
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(111)
local_vals['house'] = local_prod['param2']
no_tracts['test'] = 0
no_tracts.plot('test', cmap='copper', ax=ax)
local_vals.plot('house', cmap='Reds', ax=ax)
plt.legend()
plt.xlim(-74.02, -73.95)
plt.ylim(40.7, 40.78)
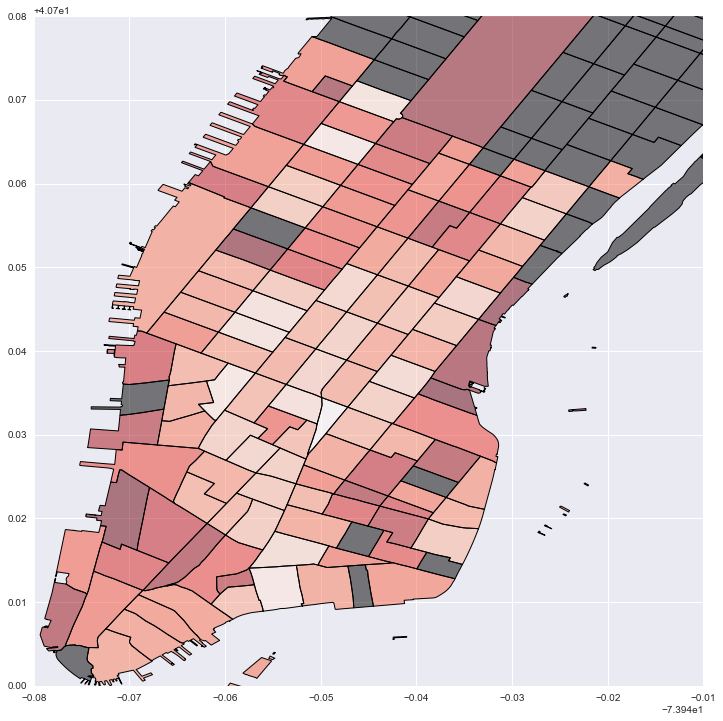
#Plot local estimates for destination building sq footage: darker red is larger effect; grey is no data
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(111)
local_vals['foot'] = local_prod['param1']
no_tracts['test'] = 0
no_tracts.plot('test', cmap='copper', ax=ax)
local_vals.plot('foot', cmap='Reds', ax=ax)
plt.legend()
plt.xlim(-74.02, -73.95)
plt.ylim(40.7, 40.78)
#Drop NA values
labels = ['start station longitude', 'start station latitude', 'end station longitude', 'end station latitude']
bikes = bikes.dropna(subset=labels)
#Prep OD data as vectors and then compute origin or destination focused distance-based weights
ids = bikes['index'].reshape((-1,1))
origin_x = bikes['SX'].reshape((-1,1))
origin_y = bikes['SY'].reshape((-1,1))
dest_x = bikes['EX'].reshape((-1,1))
dest_y = bikes['EY'].reshape((-1,1))
vecs = np.hstack([ids, origin_x, origin_y, dest_x, dest_y])
origins = vecs[:,1:3]
wo = ps.weights.DistanceBand(origins, 999, alpha=-1.5, binary=False, build_sp=False, silent=True)
dests = vecs[:,3:5]
wd = ps.weights.DistanceBand(dests, 999, alpha=-1.5, binary=False, build_sp=False, silent=True)
#Origin focused Moran's I of OD pairs as vectors in space
vmo = VecMoran(vecs, wo, permutations=1)
vmo.I
#Destination focused Moran's I of OD pairs as vectors in space
vmd = VecMoran(vecs, wd, permutations=1)
vmd.I
#No substantial examples to show for spatial interaction weights
#Will add them once there is a working SAR Lag spatial interaction
#model implementation avaialble
#from pysal.weights.spintW import vecW, netW, ODW