Distance Based Statistical Method for Planar Point Patterns
Authors: Serge Rey sjsrey@gmail.com and Wei Kang weikang9009@gmail.com
Introduction
Distance based methods for point patterns are of three types:
- Mean Nearest Neighbor Distance Statistics
- Nearest Neighbor Distance Functions
- Interevent Distance Functions
In addition, we are going to introduce a computational technique Simulation Envelopes to aid in making inferences about the data generating process. An example is used to demonstrate how to use and interprete simulation envelopes.
import scipy.spatial
import libpysal as ps
import numpy as np
from pointpats import PointPattern, PoissonPointProcess, as_window, G, F, J, K, L, Genv, Fenv, Jenv, Kenv, Lenv
%matplotlib inline
import matplotlib.pyplot as plt
Mean Nearest Neighbor Distance Statistics
The nearest neighbor(s) for a point $u$ is the point(s) $N(u)$ which meet the condition $$d_{u,N(u)} \leq d_{u,j} \forall j \in S - u$$
The distance between the nearest neighbor(s) $N(u)$ and the point $u$ is nearest neighbor distance for $u$. After searching for nearest neighbor(s) for all the points and calculating the corresponding distances, we are able to calculate mean nearest neighbor distance by averaging these distances.
It was demonstrated by Clark and Evans(1954) that mean nearest neighbor distance statistics distribution is a normal distribution under null hypothesis (underlying spatial process is CSR). We can utilize the test statistics to determine whether the point pattern is the outcome of CSR. If not, is it the outcome of cluster or regular spatial process?
Mean nearest neighbor distance statistic
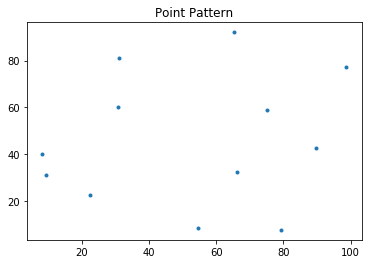
$$\bar{d}_{min}=\frac{1}{n} \sum_{i=1}^n d_{min}(s_i)$$points = [[66.22, 32.54], [22.52, 22.39], [31.01, 81.21],
[9.47, 31.02], [30.78, 60.10], [75.21, 58.93],
[79.26, 7.68], [8.23, 39.93], [98.73, 77.17],
[89.78, 42.53], [65.19, 92.08], [54.46, 8.48]]
pp = PointPattern(points)
pp.summary()
We may call the method knn in PointPattern class to find $k$ nearest neighbors for each point in the point pattern pp.
# one nearest neighbor (default)
pp.knn()
The first array is the ids of the most nearest neighbor for each point, the second array is the distance between each point and its most nearest neighbor.
# two nearest neighbors
pp.knn(2)
pp.max_nnd # Maximum nearest neighbor distance
pp.min_nnd # Minimum nearest neighbor distance
pp.mean_nnd # mean nearest neighbor distance
pp.nnd # Nearest neighbor distances
pp.nnd.sum()/pp.n # same as pp.mean_nnd
pp.plot()
Nearest Neighbor Distance Functions
Nearest neighbour distance distribution functions (including the nearest “event-to-event” and “point-event” distance distribution functions) of a point process are cumulative distribution functions of several kinds -- $G, F, J$. By comparing the distance function of the observed point pattern with that of the point pattern from a CSR process, we are able to infer whether the underlying spatial process of the observed point pattern is CSR or not for a given confidence level.
$G$ function - event-to-event
The $G$ function is defined as follows: for a given distance $d$, $G(d)$ is the proportion of nearest neighbor distances that are less than $d$. $$G(d) = \sum_{i=1}^n \frac{ \phi_i^d}{n}$$
$$ \phi_i^d = \begin{cases} 1 & \quad \text{if } d_{min}(s_i)<d \\ 0 & \quad \text{otherwise } \\ \end{cases} $$If the underlying point process is a CSR process, $G$ function has an expectation of: $$ G(d) = 1-e(-\lambda \pi d^2) $$ However, if the $G$ function plot is above the expectation this reflects clustering, while departures below expectation reflect dispersion.
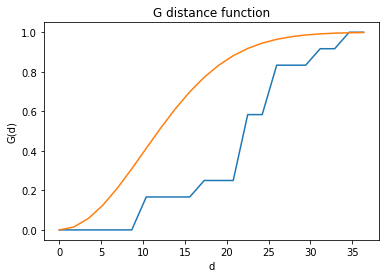
gp1 = G(pp, intervals=20)
gp1.plot()
A slightly different visualization of the empirical function is the quantile-quantile plot:
gp1.plot(qq=True)
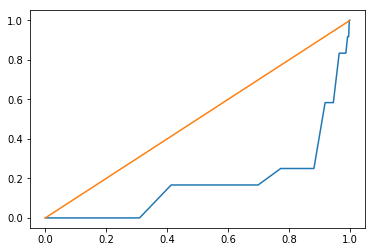
in the q-q plot the csr function is now a diagonal line which serves to make accessment of departures from csr visually easier.
It is obvious that the above $G$ increases very slowly at small distances and the line is below the expected value for a CSR process (green line). We might think that the underlying spatial process is regular point process. However, this visual inspection is not enough for a final conclusion. In Simulation Envelopes, we are going to demonstrate how to simulate data under CSR many times and construct the $95\%$ simulation envelope for $G$.
gp1.d # distance domain sequence (corresponding to the x-axis)
gp1.G #cumulative nearest neighbor distance distribution over d (corresponding to the y-axis))
$F$ function - "point-event"
When the number of events in a point pattern is small, $G$ function is rough (see the $G$ function plot for the 12 size point pattern above). One way to get around this is to turn to $F$ funtion where a given number of randomly distributed points are generated in the domain and the nearest event neighbor distance is calculated for each point. The cumulative distribution of all nearest event neighbor distances is called $F$ function.
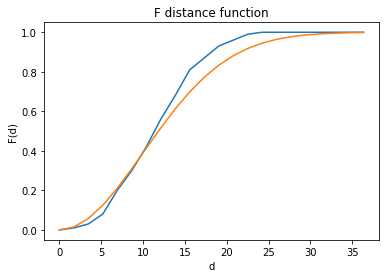
fp1 = F(pp, intervals=20) # The default is to randomly generate 100 points.
fp1.plot()
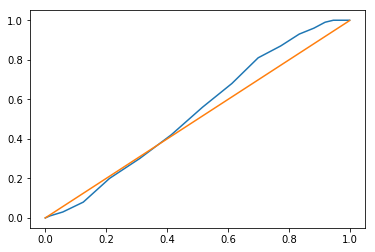
fp1.plot(qq=True)
We can increase the number of intervals to make $F$ more smooth.
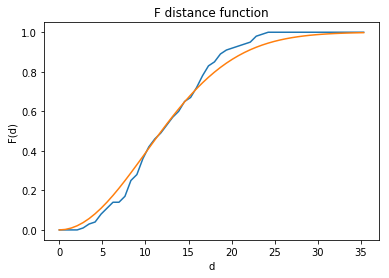
fp1 = F(pp, intervals=50)
fp1.plot()
fp1.plot(qq=True)
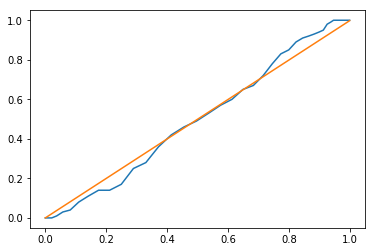
$F$ function is more smooth than $G$ function.
$J$ function - a combination of "event-event" and "point-event"
$J$ function is defined as follows:
$$J(d) = \frac{1-G(d)}{1-F(d)}$$If $J(d)<1$, the underlying point process is a cluster point process; if $J(d)=1$, the underlying point process is a random point process; otherwise, it is a regular point process.
jp1 = J(pp, intervals=20)
jp1.plot()
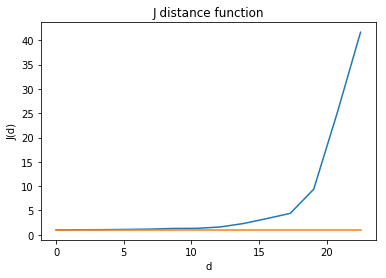
From the above figure, we can observe that $J$ function is obviously above the $J(d)=1$ horizontal line. It is approaching infinity with nearest neighbor distance increasing. We might tend to conclude that the underlying point process is a regular one.
Interevent Distance Functions
Nearest neighbor distance functions consider only the nearest neighbor distances, "event-event", "point-event" or the combination. Thus, distances to higer order neighbors are ignored, which might reveal important information regarding the point process. Interevent distance functions, including $K$ and $L$ functions, are proposed to consider distances between all pairs of event points. Similar to $G$, $F$ and $J$ functions, $K$ and $L$ functions are also cumulative distribution function.
$K$ function - "interevent"
Given distance $d$, $K(d)$ is defined as: $$K(d) = \frac{\sum_{i=1}^n \sum_{j=1}^n \psi_{ij}(d)}{n \hat{\lambda}}$$
where $$ \psi_{ij}(d) = \begin{cases} 1 & \quad \text{if } d_{ij}<d \\ 0 & \quad \text{otherwise } \\ \end{cases} $$
$\sum_{j=1}^n \psi_{ij}(d)$ is the number of events within a circle of radius $d$ centered on event $s_i$ .
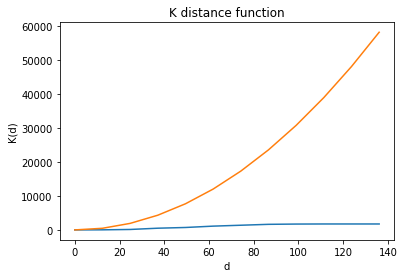
Still, we use CSR as the benchmark (null hypothesis) and see how the $K$ funtion estimated from the observed point pattern deviate from that under CSR, which is $K(d)=\pi d^2$. $K(d)<\pi d^2$ indicates that the underlying point process is a regular point process. $K(d)>\pi d^2$ indicates that the underlying point process is a cluster point process.
kp1 = K(pp)
kp1.plot()
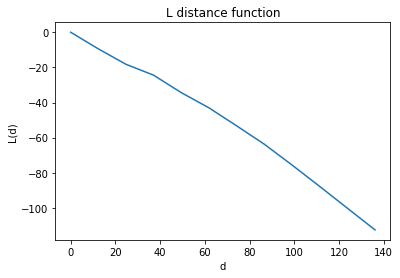
lp1 = L(pp)
lp1.plot()
Simulation Envelopes
A Simulation envelope is a computer intensive technique for inferring whether an observed pattern significantly deviates from what would be expected under a specific process. Here, we always use CSR as the benchmark. In order to construct a simulation envelope for a given function, we need to simulate CSR a lot of times, say $1000$ times. Then, we can calculate the function for each simulated point pattern. For every distance $d$, we sort the function values of the $1000$ simulated point patterns. Given a confidence level, say $95\%$, we can acquire the $25$th and $975$th value for every distance $d$. Thus, a simulation envelope is constructed.
realizations = PoissonPointProcess(pp.window, pp.n, 100, asPP=True) # simulate CSR 100 times
genv = Genv(pp, intervals=20, realizations=realizations) # call Genv to generate simulation envelope
genv
genv.observed
genv.plot()
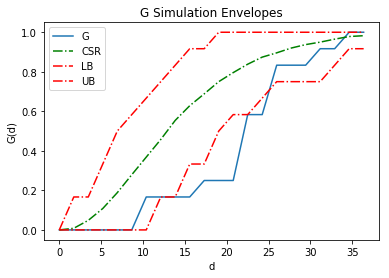
In the above figure, LB and UB comprise the simulation envelope. CSR is the mean function calculated from the simulated data. G is the function estimated from the observed point pattern. It is well below the simulation envelope. We can infer that the underlying point process is a regular one.
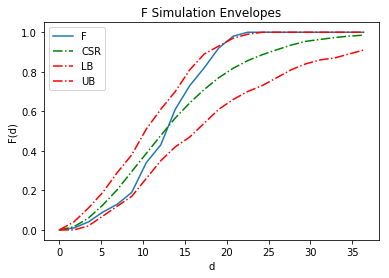
fenv = Fenv(pp, intervals=20, realizations=realizations)
fenv.plot()
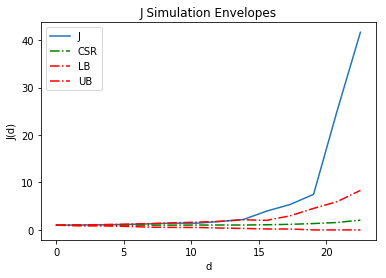
jenv = Jenv(pp, intervals=20, realizations=realizations)
jenv.plot()
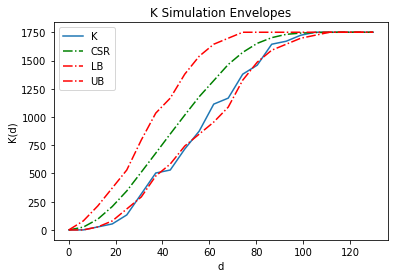
kenv = Kenv(pp, intervals=20, realizations=realizations)
kenv.plot()
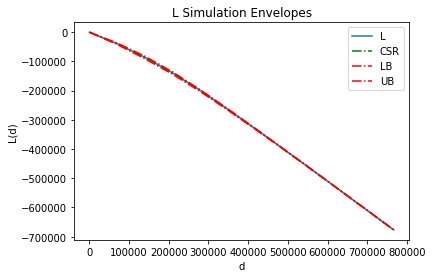
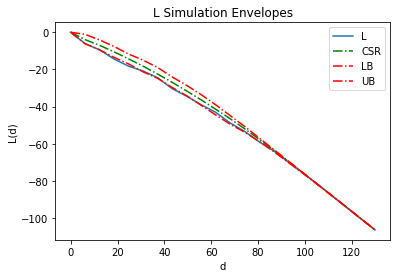
lenv = Lenv(pp, intervals=20, realizations=realizations)
lenv.plot()
from libpysal.cg import shapely_ext
from pointpats import Window
import libpysal as ps
va = ps.io.open(ps.examples.get_path("vautm17n.shp"))
polys = [shp for shp in va]
state = shapely_ext.cascaded_union(polys)
Generate the point pattern pp (size 100) from CSR as the "observed" point pattern.
a = [[1],[1,2]]
np.asarray(a)
n = 100
samples = 1
pp = PoissonPointProcess(Window(state.parts), n, samples, asPP=True)
pp.realizations[0]
pp.n
Simulate CSR in the same domian for 100 times which would be used for constructing simulation envelope under the null hypothesis of CSR.
csrs = PoissonPointProcess(pp.window, 100, 100, asPP=True)
csrs
Construct the simulation envelope for $G$ function.
genv = Genv(pp.realizations[0], realizations=csrs)
genv.plot()
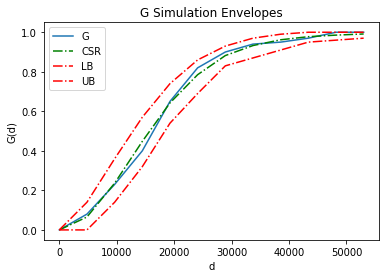
Since the "observed" $G$ is well contained by the simulation envelope, we infer that the underlying point process is a random process.
genv.low # lower bound of the simulation envelope for G
genv.high # higher bound of the simulation envelope for G
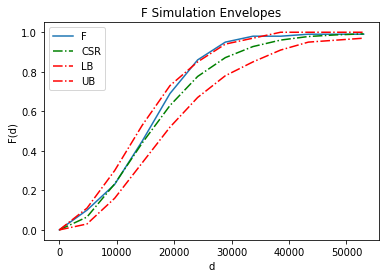
Construct the simulation envelope for $F$ function.
fenv = Fenv(pp.realizations[0], realizations=csrs)
fenv.plot()
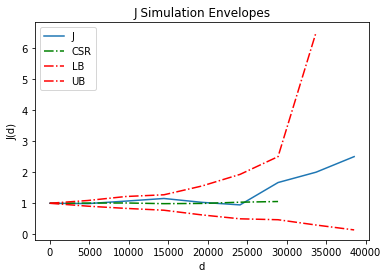
Construct the simulation envelope for $J$ function.
jenv = Jenv(pp.realizations[0], realizations=csrs)
jenv.plot()
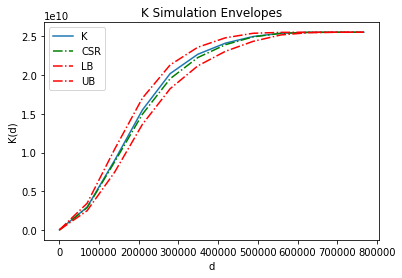
Construct the simulation envelope for $K$ function.
kenv = Kenv(pp.realizations[0], realizations=csrs)
kenv.plot()
Construct the simulation envelope for $L$ function.
lenv = Lenv(pp.realizations[0], realizations=csrs)
lenv.plot()