This page was generated from notebooks/DirectionalLISA.ipynb.
Interactive online version:
![]()
Directional Analysis of Dynamic LISAs¶
This notebook demonstrates how to use Rose diagram based inference for directional LISAs.
[1]:
import numpy as np
import warnings
with warnings.catch_warnings():
warnings.simplefilter("ignore")
# ignore NumbaDeprecationWarning: gh-pysal/libpysal#560
import libpysal
from giddy.directional import Rose
[2]:
f = open(libpysal.examples.get_path("spi_download.csv"), "r")
lines = f.readlines()
f.close()
[3]:
lines = [line.strip().split(",") for line in lines]
names = [line[2] for line in lines[1:-5]]
data = np.array([list(map(int, line[3:])) for line in lines[1:-5]])
[4]:
sids = list(range(60))
out = [
'"United States 3/"',
'"Alaska 3/"',
'"District of Columbia"',
'"Hawaii 3/"',
'"New England"',
'"Mideast"',
'"Great Lakes"',
'"Plains"',
'"Southeast"',
'"Southwest"',
'"Rocky Mountain"',
'"Far West 3/"',
]
[5]:
snames = [name for name in names if name not in out]
[6]:
sids = [names.index(name) for name in snames]
[7]:
states = data[sids, :]
us = data[0]
years = np.arange(1969, 2009)
[8]:
rel = states / (us * 1.0)
[9]:
gal = libpysal.io.open(libpysal.examples.get_path("states48.gal"))
w = gal.read()
w.transform = "r"
[10]:
Y = rel[:, [0, -1]]
[11]:
Y.shape
[11]:
(48, 2)
[12]:
Y
[12]:
array([[0.71272158, 0.83983287],
[0.91110532, 0.85393454],
[0.68196038, 0.80573518],
[1.181439 , 1.08538102],
[0.96115746, 1.06906586],
[1.25677789, 1.39952248],
[1.14859228, 1.00773478],
[0.9535975 , 0.9765967 ],
[0.82090719, 0.86781238],
[0.85088634, 0.82257262],
[1.12956204, 1.05319837],
[0.9624609 , 0.86064962],
[0.95542231, 0.93021289],
[0.92674661, 0.96547951],
[0.77267987, 0.79775169],
[0.75234619, 0.90588938],
[0.81803962, 0.90671011],
[1.09462982, 1.20319339],
[1.09098019, 1.27472145],
[1.08107404, 0.86920513],
[0.98409802, 1.07035913],
[0.62643379, 0.75604357],
[0.93039625, 0.9110376 ],
[0.85870699, 0.86161958],
[0.93091762, 0.97368683],
[1.18091762, 1.02422404],
[0.97627737, 1.08493335],
[1.17309698, 1.277308 ],
[0.76120959, 0.83142658],
[1.19212722, 1.2125199 ],
[0.79405631, 0.87902905],
[0.80787278, 0.99159371],
[1.01955162, 0.89586649],
[0.83524505, 0.89497115],
[0.9580292 , 0.9027308 ],
[0.99165798, 0.99830879],
[1.00286757, 1.02884998],
[0.73540146, 0.81242539],
[0.7898853 , 0.96152507],
[0.77085506, 0.86987664],
[0.87695516, 0.93946478],
[0.80943691, 0.79446876],
[0.88112617, 0.96214684],
[0.92805005, 1.09988062],
[1.06491137, 1.06588241],
[0.7278415 , 0.78693295],
[0.97679875, 0.93929069],
[0.93508863, 1.20891365]])
[13]:
np.random.seed(100)
r4 = Rose(Y, w, k=4)
Visualization¶
[14]:
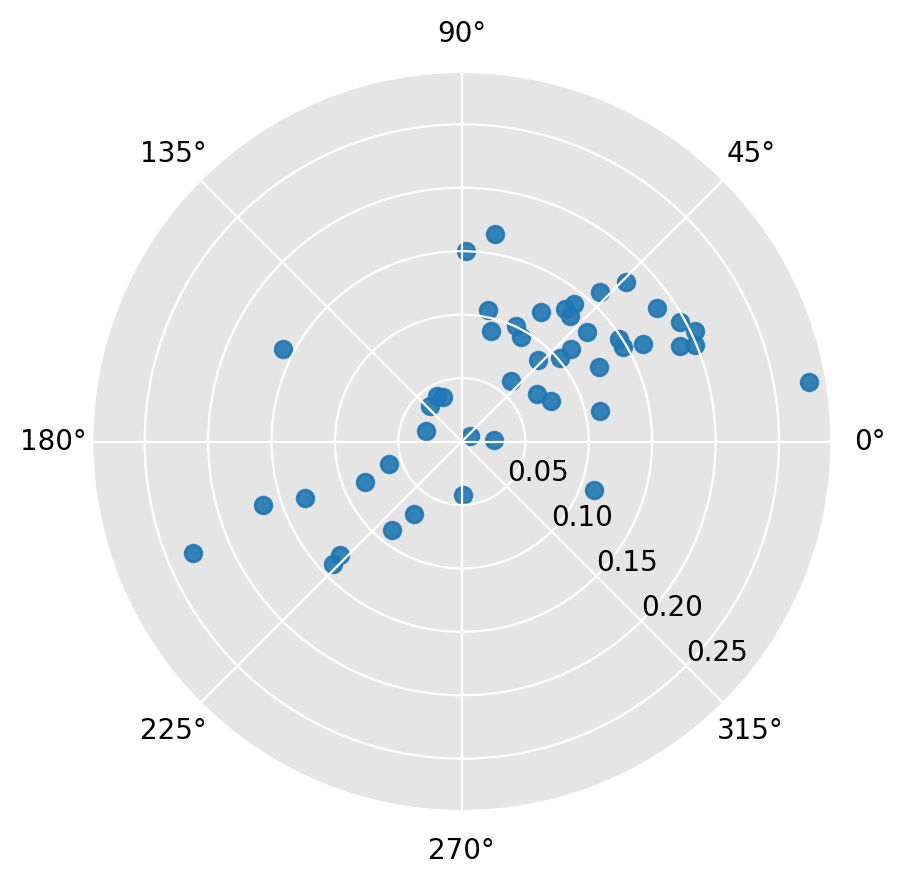
r4.plot(cmap=None)
[14]:
(<Figure size 640x480 with 1 Axes>, <PolarAxes: >)
[15]:
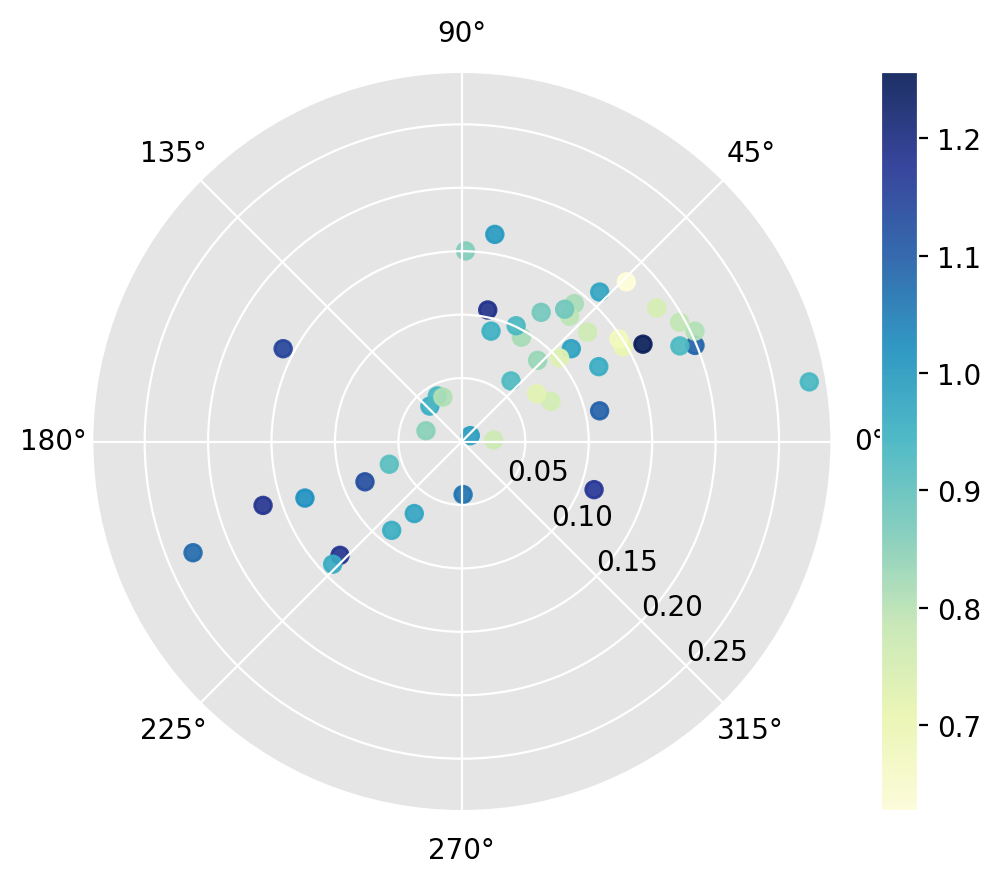
r4.plot(Y[:, 0]) # condition on starting relative income
[15]:
(<Figure size 640x480 with 2 Axes>, <PolarAxes: >)
[16]:
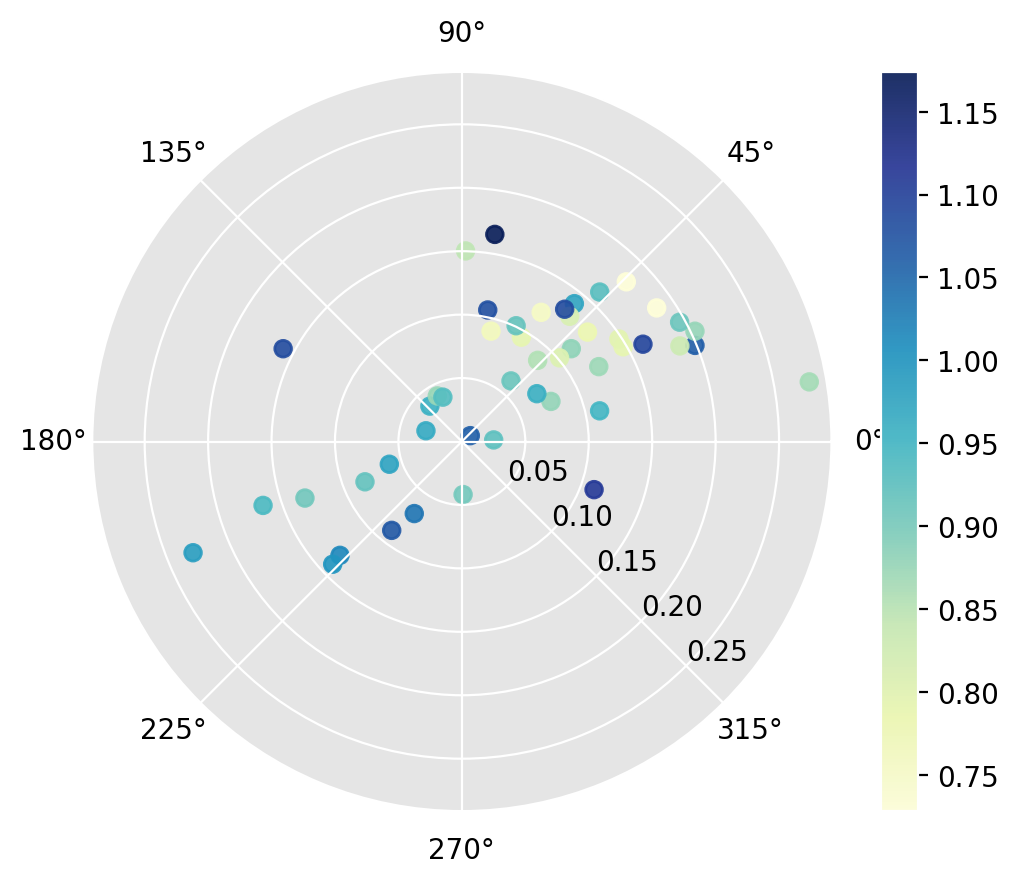
r4.plot(
attribute=r4.lag[:, 0]
) # condition on the spatial lag of starting relative income
[16]:
(<Figure size 640x480 with 2 Axes>, <PolarAxes: >)
[17]:
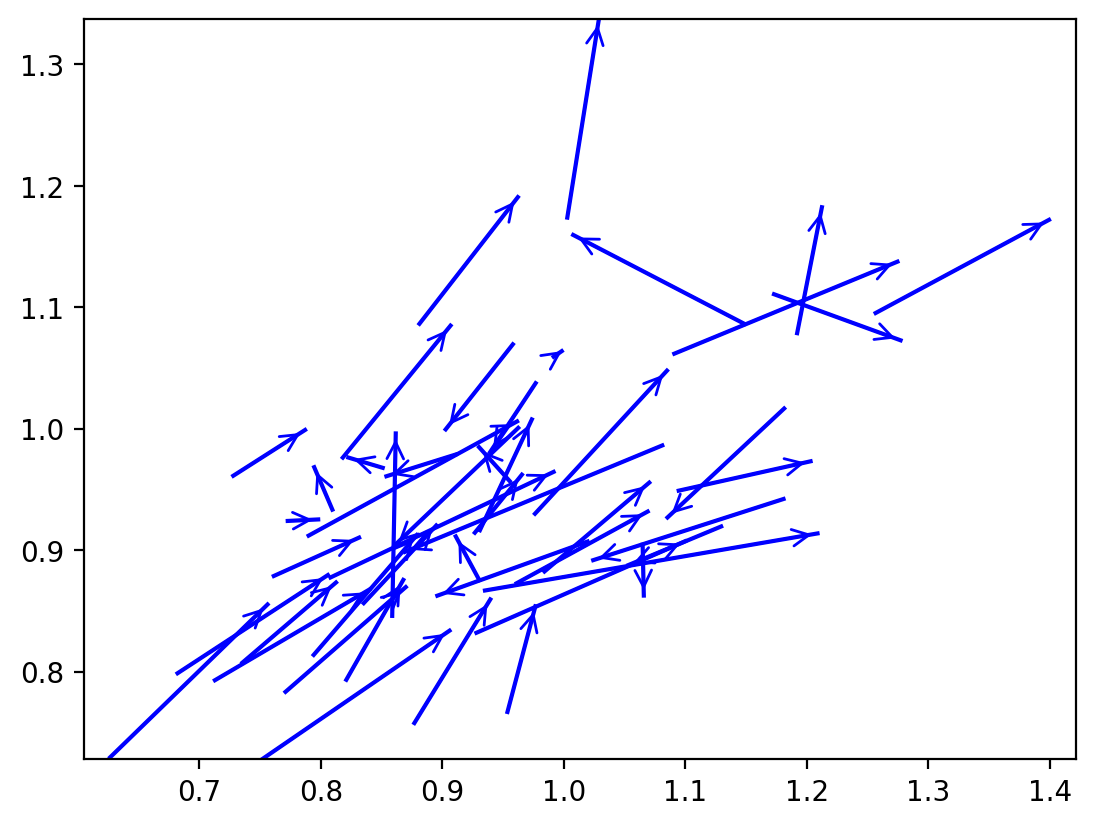
r4.plot_vectors() # lisa vectors
[17]:
(<Figure size 640x480 with 1 Axes>, <Axes: >)
[18]:
r4.plot_vectors(arrows=False)
[18]:
(<Figure size 640x480 with 1 Axes>, <Axes: >)
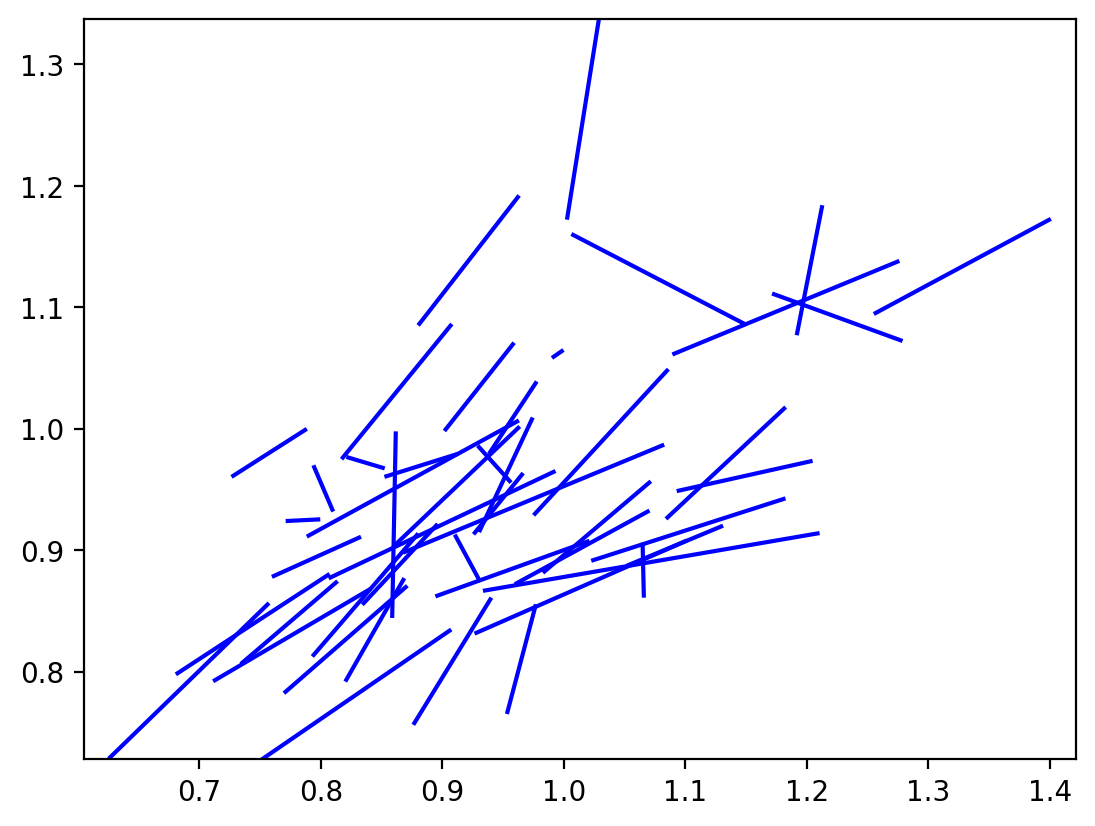
[19]:
r4.plot_origin() # origin standardized
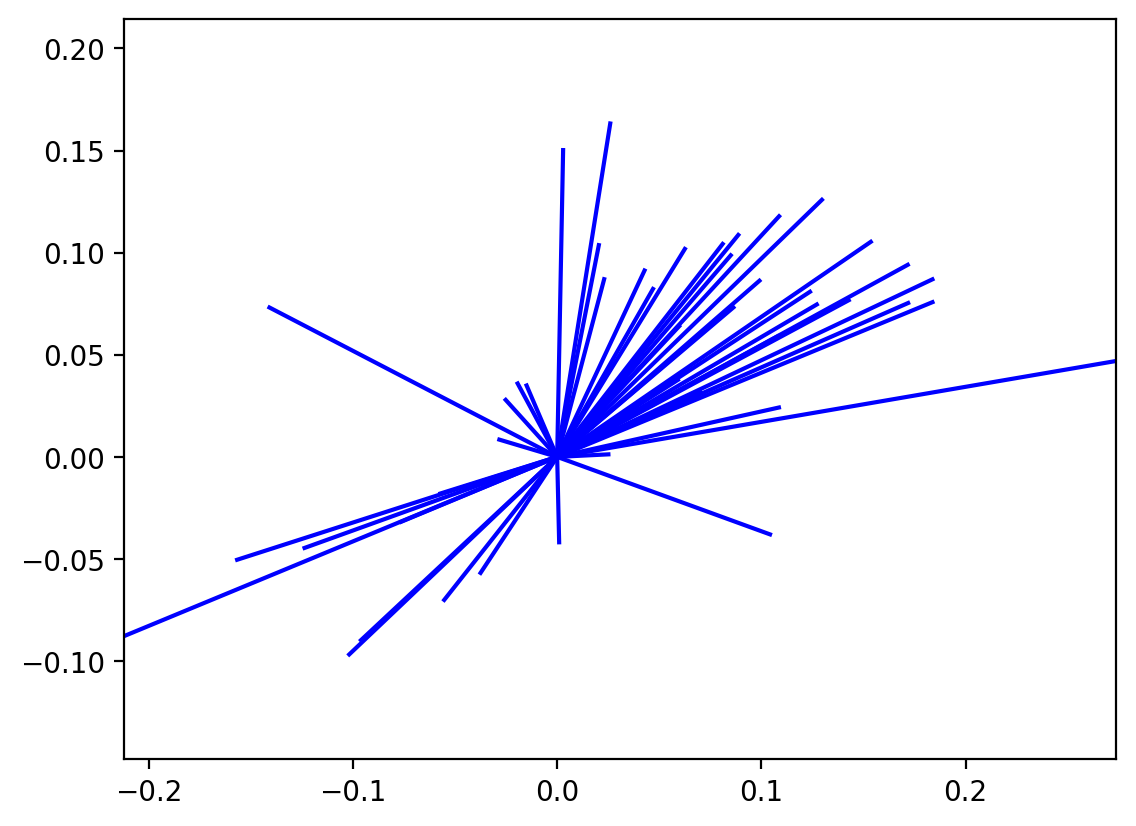
Inference¶
The Rose class contains methods to carry out inference on the circular distribution of the LISA vectors. The first approach is based on a two-sided alternative where the null is that the distribution of the vectors across the segments reflects independence in the movements of the focal unit and its spatial lag. Inference is based on random spatial permutations under the null.
[20]:
r4.cuts
[20]:
array([0. , 1.57079633, 3.14159265, 4.71238898, 6.28318531])
[21]:
r4.counts
[21]:
array([32, 5, 9, 2])
[22]:
np.random.seed(1234)
[23]:
r4.permute(permutations=999)
[24]:
r4.p
[24]:
array([0.028, 0. , 0.002, 0.004])
Here all the four sector counts are signficantly different from their expectation under the null.
A directional test can also be implemented. Here the direction of the departure from the null due to positive co-movement of a focal unit and its spatial lag over the time period results in two two general cases. For sectors in the positive quadrants (I and III), the observed counts are considered extreme if they are larger than expectation, while for the negative quadrants (II, IV) the observed counts are considered extreme if they are small than the expected counts under the null.
[25]:
r4.permute(alternative="positive", permutations=999)
r4.p
[25]:
array([0.013, 0.001, 0.001, 0.013])
[26]:
r4.expected_perm
[26]:
array([27.24824825, 11.56556557, 2.43443443, 6.75175175])
Finally, a directional alternative reflecting negative association between the movement of the focal unit and its lag has the complimentary interpretation to the positive alternative: lower counts in I and III, and higher counts in II and IV relative to the null.
[27]:
r4.permute(alternative="negative", permutations=999)
r4.p
[27]:
array([0.996, 1. , 1. , 0.996])